
You may have seen the term TF IDF being tossed around in the last year or so, but no one could blame you if you haven’t started paying attention yet.
A lot of SEO fads come and go, and some of the most interesting concepts just end up attracting penalties, later on, right?
But TF IDF is something a little different.
It’s not a manipulation of Google search results; it’s a method of analyzing the topics in content, and it’s built on the same principles as the search engines themselves. Because of that, it has amazing potential for SEOs who need a truly objective method to measure and improve content.
I just recently wrapped up a case study into exactly what it’s capable of, and the results are quite interesting.
In case some of you are where I was only a few months ago, I want to make sure that I cover what I learned about TF IDF, and how it’s used before I get to what I learned from my personal experiments with it.
The crash course starts in the next section, but if you’re an experienced user already, you can find the results of my personal tests and some comparisons of the top TF IDF tools near the end.
Looking forward to your questions and comments.
Table Of Contents
Quick Summary
 TF*IDF (Term Frequency-Inverse Document Frequency) is a numerical statistic used in SEO to reflect how important a word is to a document in a collection or corpus.
TF*IDF (Term Frequency-Inverse Document Frequency) is a numerical statistic used in SEO to reflect how important a word is to a document in a collection or corpus.- While TF*IDF doesn’t directly impact rankings, it can indirectly influence them by improving the relevance and comprehensiveness of content.
- In our tests, SurferSEO was the most accurate TF*IDF tool.
What is TF IDF?
Term Frequency times Inverse Document Frequency (TF*IDF) is an equation that uses the measurement of how frequently a term is used on a page (TF), and the measurement of how often that term appears on all pages of a collection (IDF) to assign a score, or weight, to the importance of that term to the page.

I know… nerd alert, right?
We’ll look at why this is so important to SEOs in a bit, but first, let’s look at where it came from.
The equation has a very long history in academia, where researchers in fields as diverse as linguistics and information architecture have used it to analyze massive libraries of documents quickly.
It’s also used by information retrieval programs (including all search engines) to sort and judge the relevance of millions of search results efficiently.
There is an important difference between what you want to do and what the search engine wants to do with this same information.
The search engine wants to consider a collection made up of all the search results on the web while you want to compare one page or website to just the sites that are out-performing it…. namely the top 10.
Let’s look at TF and IDF in more depth…
The Equations that take you to TF*IDF

You need to do a little more math to get both of the measurements involved, that is TF and IDF. but I promise it won’t be difficult. Depending on the application, the equations for TF IDF can get a lot more complicated than the examples I’m using below.
Simplified or not, you generally don’t want to be caught doing this work by hand if you’re trying to optimize a site. These equations will help you understand how TF IDF functions, but it’s the content optimization tools I’m discussing at the end that really open up the potential.
Solve the first one, Term Frequency, by doing a raw count of the number of times a term appears on one page. Then, plug that number into the equation below:
Term frequency = (raw count of terms) / (total word count of document)
Alone, the TF score can tell you whether you’re using a word too rarely or too often, but it’s only really useful when weighed against the other measure.
Calculate the Inverse Document Frequency by dividing the number of documents the term appears in by the total number of documents in the chosen collection, like so:
Inverse Document Frequency (term) = log (number of docs / (docs containing keyword)
With the IDF score, you can now measure the importance of a target keyword/phrase to a page, not just its number of uses. This is important because it’s putting you in the mindset of the people who are building search engine algorithms.
Why Does TF*IDF Matter to SEOs?
TF*IDF matters because, with the help of this equation, SEOs are able to an actionable relevance score to their content. Using TF IDF tools available, you can then compare your scores to the scores of the top-performing pages for any term.
By grading pages on this measure, you can nearly pull back the curtain on how Google might grade sites dedicated to the same topic.
It’s unknown if Google uses TF IDF in its algorithm, and if they are, is it a mutated form of it or not? That said, there have been some private correlation studies that I’ve been privy to whose data suggests that it’s likely.
TF IDF analysis allows you to optimize the balance of terms in your content according to what is already being rewarded by the algorithm.
That’s huge for the SEO community because it marks the return of something all the old hats knew and…loved?
Keyword Density Returns?

Nope. No one loved the days when keyword density reigned.
However, using TF IDF for SEO could mark a return to the primacy of phrases and keywords as an important marker—just in a very different way.
The thing is, Google never even relied on the density of keywords as a measure of value. It just appeared as if they did to people who didn’t understand how the algorithm really worked.
Instead, that SEO strategy was an early attempt to game out how Google was really using TF IDF for its indexing and recall.
People were keyword stuffing their blog posts, so then algos and filters came out to combat it (hi, panda).
So, in a way, keyword density is back. It ran away from home as a surly teen and has returned as a mature adult with a degree in the sciences.
It was an early, limited tactic that mostly encouraged bad habits. Measuring keyword use TF IDF will give you an idea (at least as far as the top search results are using them) balance. It reveals what terms are considered natural, in a very precise way.
Using TF IDF Analysis to Enhance Keyword Research
TF IDF analysis goes a step further than just the density of keywords. In this way, it opens you to insights about whole families of words on a website, which can take your keyword research to the next level.
For example, imagine that you’ve already completed keyword research to optimize a page for “DUI lawyer Chicago”. Most research tools for keywords will spit out keywords like “DUI lawyer in chicago”, “chicago DUI attorney”, etc.
When you use the TF IDF tools that I’m covering later on, you’ll also be able to find related non-SEO terms that are being used by the top-ranked pages that you would have never found before using normal keyword research. Terms like “legal”, “experienced”, “rights” and “practice”.

These words wouldn’t have shown up in keyword research tools because the articles themselves aren’t ranking for them, yet they’re needed to tell the story of the search intent.
Let’s put the equation to use.
Fortunately, you won’t need to do it by hand for your sites. There’s always a tool to use, and you’re only a few scrolls from seeing the on-page SEO tools I’ve tested for results.
Putting TF*IDF Analysis to Use
Oh, no. More math.
At this point you may be having high school flashbacks, twisting around in your chair looking desperately for the wall clock that will tell you when you’re free.
Don’t worry, this time, I’m going to do the math. Immediately after this, we’ll get to the juicy stuff—How to use TF IDF for SEO purposes.
Let’s take a look at the equation in action…
Say that a document, such as a client’s landing page you’re examining, contains the keyword “PPC” 12 times, and is about 100 words in length. If you wanted to begin analyzing this piece of content, you would begin by plugging that into the term frequency equation from earlier.
TF (PPC) = (12 / 100) = 0 .12
Now, say that you wanted to understand how this usage compared to the usage of this term on the rest of the web. From a sample size of 10,000,000, at least some of these pages are going to be about web services and will include references to PPC. Let’s say, 300,000 of them.
We can use those numbers to finish the Inverse Document Frequency equation.
IDF (PPC) = log (10,000,000/300,000) = 1.52
Now you score your page based on that term with the TF*IDF equation
TF*IDF (PPC) = 0.12 * 1.52 = 0.182
That’s a great score. Or is it?
The truth is, it’s not really a matter of meeting a limit. You want to bring your score for targeted terms into balance with the best-performing URLs on page 1.
A high score for a certain term isn’t necessarily a good thing (12 uses in 100 words is a lot, after all).
What about Common Terms like “the” and “of”?
You may be wondering, what about the noise?
What about all the common words like “of”, “the” or “and”? Because of the way the equation is structured, this noise isn’t really a problem.
The entire set of documents uses these words frequently, so the prominence of those words is scaled down considerably.
Let’s go back to the equation. To really illustrate the difference, we’ll say that there are as many uses of “of” on the page as there are of “PPC”.
TF (OF) = (12 /100) = 0 .12
But look what happens when we finish the IDF equation with the knowledge that the vast majority of search results will contain the word “of”, say 8,000,000 of them.
IDF (OF) = log (10,000,000/8,000,000) = 0.09
That would make the final TF IDF value:
TF*IDF (OF) = 0 .12 * 0.09 = 0.010
The TF IDF value increases proportionally to the number of times the phrase is used in the document, but in this case, it is so offset by the frequency of the word throughout the rest of the collection, that its value score is cratered compared to the last example.
In other words, the more common the word is, the smaller the inverse document frequency becomes.
What about Phrases?
Google tend to give an outsize weight to multi-word phrases over single terms.

This is especially true when the natural quality of language is being considered.
Naturally, you want to carry these considerations over to how you perform your TF IDF assessments.
Fortunately, that takes no extra effort on your part. Most TF IDF tools are capable of calculating keywords as 2-word and 3-word versions.
When TF IDF was used exclusively for academic and research purposes, terms were already calculated as either 2-word sets called bigrams, or 3-word sets called trigrams. That same practice was adopted by search engines, so it’s important to analyze your content the same way they do.
Using the example of a PPC page from before, let’s look at a phrase that might appear on that page, and what the phrases may suggest about the topic.
“A PPC campaign needs many ads”
Each set of two words in this phrase could be calculated as a set of bigrams.
- A PPC
- PPC campaign
- campaign needs
- etc.
When a third word is added, it becomes even clearer how much important context is added when longer phrases are considered.
- A PPC Campaign
- PPC campaign needs
- campaign needs many
- etc.
Not all TF IDF tools are capable of handling more than two combinations. I’ll go into more detail into the capabilities of each in the tool comparison located further down.
How to use TF*IDF
TF IDF fits neatly into the content development process of almost any SEO.
It’s a method of learning more while you’ve started building content’s SEO strategy, and then knowing where and how to perfect it again.
Once you’ve chosen a tool, only it’s a step-by-step process to get more insight into each keyword choice. If you have not chosen a TF IDF tool yet, you can find the data from the tests I performed with them in the next section.
1) Write content

Write content to the highest standards you know, or refer to a piece of content that you’re optimizing for a client. Create a list of one, two or three-word topics that you want to cover and take it to the TF*IDF tool that you’ve chosen.
Your goal here is to target keywords and the URLs of the top domains that target them to reveal what topics you are missing and what topics you aren’t covering in enough depth.
2) Plug into a TF*IDF tool
Each tool works slightly differently, as you’ll be able to see below. They also track different information, but the most useful on-page SEO tools are geared toward helping you understand how your competitors are finding success with their use of keywords.
Take advantage of any features your chosen tool has to help you discover terms that are associated with the top 10-20 top-ranking URLs, and then produce scores that reflect the weight of each other term they’re using.
3) Re-optimize content
Now that you have a complete idea of the topics covered by each of your competitors and an understanding of how frequently those words are used, you can use that information to refine your own content.
Take a second pass at the content and look for natural ways to introduce topics that you haven’t covered yet. Remember, your motivation is not to do keyword stuffing unnaturally, but to restore natural connections where they’re currently missing.
4) Publish
Publish the content updated with the insights you’ve recently gleaned from your analysis of the google search results. From here, you can continue to analyze it, and any changes in the ranks.
5) Show before and after TF*IDF Search results

One of the rewards of TF*IDF is that it allows you to track performance at a very minute level. Before and after each adjustment you make to your content, you can produce screenshots of how the balance of topics on your pages has changed. These are useful to clients who are interested in seeing specific target keyword metrics for changes you’re making in their content.
Now, we’re ready to get into the part you’ve been waiting for!
I’ve had a chance to play with all of the biggest TF*IDF tools on my own sites, and I have a lot to show you about what they can do.
But first, let me share some results I’ve gotten from testing TF*IDF in the actual Interwebs.
Testing Results
I’d like to preface this section by saying that I’ve actually been testing TF*IDF for over a year.
Ever since I first looked into niche-based semantic density algorithms, the concept struck a harmonious chord with me.
And although the right mindset going into any kind of experimentation is agnosticism, I really wanted TF*IDF to work.
That said… for a very long time, I got lackluster results.
And then things changed.
I’m about to walk you through the timeline, but first, let me describe how I tested it.
Identifying Testcases for TF*IDF Experiments
Creating single-variable test structures is quite challenging for this particular scenario.

What is a single variable test?
In a super controlled test environment, you would have two groups of testcases.
One group would be the control group.
In the control group, you don’t change anything. You’re simply getting a “baseline” result to compare against the experimental group.
The experimental group is completely identical to the control group in most regards.
The web pages might have the same types of backlinks, target the same keyword, etc. All these variables must be similar and constant between each other, or else the test is flawed.
However, with the experimental group, you change one thing. This is the “single variable”. And in this case, it would be TF*IDF optimization.
For the websites in the experimental group, you would perform TF*IDF optimization, let them sit, and then compare the results against the control group.
The challenge with SEO testing is that you can never control all the variables. There’s always noise coming along in the form of backlinks, traffic, competition, algorithm changes, etc.
You know how SEO is. It’s noisy AF.
One way people like to create SEO tests is by using gibberish words.
Let’s say we create 10 inner-pages on the same domain, all targeting some made-up word like “flubblegoblin”.
They’d take up the top 10 spots in Google since there’s no search results for “flubblegoblin” (yet).

These pages would be very similar in length, optimization, etc.
You could then optimize three of them with TF*IDF, let them sit, and then if TF*IDF works, they should start ranking #1-3, right?
But this approach is flawed from the start.
You’d have to optimize their content with respect to all the other pages you’ve built, which were already created similarly to each other.
Thus, if you set up the experiment correctly from the beginning, there would be no optimization possible. They’re already identical.
So dead end here too.
Alas, I went with the following approach to testing.
I would isolate multiple pages on multiple live websites that had the following characteristics:
- Static rankings for at least a month’s time
- Not receiving any backlinks or internal link juice
I would then apply TF IDF content optimization and let them sit for about 30 days and look out for increases or decreases in rankings.
I’m not entirely happy with this approach as a lot of “noise” can enter in this experiment structure from algorithm changes, the websites aging themselves, etc.
So, I decided to combat this inaccuracy, by testing over multiple phases and many different pages.
Now onto the show.
Phase 1 – Between December and March
Aka, the dark ages.
Optimization tools:
- From the Future’s free tool
- Text-tools.net (Use code MATT-TFIDF for 35% off)
My first experiments with TF*IDF optimization were run between the dates mentioned above.
I ran experiments on three different occasions, on 12 different URLs, and tracked 36 different keywords (3 per URL).
In each case, the results were left to settle for 45 days (just in case).
Here are the lackluster results:

Whomp whomp.
There didn’t seem to be much effect in either the positive or negative direction.
After so much testing and results like these, why did I continue?
Because, as I mentioned before, I was really into the concept and I was (to be frank) quite surprised it didn’t do anything.
I started doubting my testcase integrity and the tools I was using.
Eventually, I just told myself I would continue to test this periodically just to “checkup” on things.
Phase 2 – April
For this second round of testing, I decided to stick to Text Tools for the analysis and content optimization.
Why?
For one because the software allowed for in-tool adjustments, so I could edit my text and re-evaluate on the fly (I’ll be doing a tool review later in this article).
And two, because the owner gave me a free license (thanks Michael).
I was surprised to see the following results the 2nd time around.

On two of the three testcases, we experienced positive movement.
It wasn’t groundbreaking movement, but enough to show a trend.
But here was the kicker.
During this point in time, a core algorithm update was released. It happened in March to be exact.
The two sites that showed positive movement were currently getting beat-up by this algorithm update.
And while all pages on the site were experiencing a loss in rankings, the pages where I was testing TF IDF tool either held their ground or gained rankings.
And then I found articles like this…

If these algorithm updates were about relevance, then what better indicator of relevance than the damn words that appear on web pages.
The coincidence was enough to peak my interest.
Was it enough for me to completely sign off on TF IDF and add it to my standard operating procedures (SOP)?
Absolutely not.
Only more testing could do that.
Phase 3 – May
Nothing changed in this experiment.
I continued to use Text Tools as my software of choice.
The only thing different was new testcases and a different date.

The trends remained the same as in phase 2.
More positive results.
This time I dug into things and noticed some patterns.
Results typically get worse before they get better
In 61% of the keywords I was tracking, the keywords got worse before they got better.
Only after 22-24 days after the initial kick-off and re-caching of the new optimized text did the rankings start to turn the corner.
By optimizing one keyword, you might deoptimize another
I do a lot of affiliate SEO, so most of the pages I was experimenting with were review pages.
So, when deciding which keywords to analyze and optimize for I would typically go for “best ___” keywords like “best protein powder”.
Yet, for the testing, I was tracking a wide range of keywords such as “protein powder benefits”.
Those keywords that aren’t really related to review-oriented queries like “best protein powder” or “protein powder reviews” were more likely to experience negative movement.
Phase 4 – August
This time around I decided to use a different tool: Link Assistant’s Website Auditor.
I switched things up from Text Tools as there’s (what I believe to be) a flaw in its implantation, which I’ll discuss later.
Here’s the results:

At this point, I started to feel comfortable enough with the results to warrant writing this article and to start incorporating this technique into our SOP.
Especially with results like these that required zero link building:

Tool Comparison: Surfer vs Website Auditor vs Text Tools
Here’s a comparison of three of the most popular tools on the market which can be used for TF IDF content analysis and optimization: Surfer’s True Density vs Link Assistant’s Website Auditor vs Text Tools.
TF*IDF Tool Comparison
| Tool | Platform | Usability | Accuracy | Cost | Our Choice |
|---|---|---|---|---|---|
| x | x | x | x | ||
| x | |||||
Platform (Winner: Surfer)
Surfer is run in the cloud. You log in to their platform and all the onpage seo analysis is run server-side.

Obviously, this is the way most of us like to run our software these days (if possible) so we’re giving our vote to Surfer when it comes to platform.
Text Tools is also run in the cloud and has some nice graphical views (see below), but Surfer has a slight edge when it comes to the power of their platform. Surfer doesn’t just do TFIDF, it does a lot more.

Website Auditor is a downloadable piece of software. The free version of it includes TF*IDF analysis.
It’s a pretty solid tool, as you can see below.

Nonetheless, we still prefer to work on the cloud so the vote goes to Surfer.
Usability (Winner: Surfer)
Right off the bat, Website Auditor has a big strike against it since you can’t save projects.
This is a feature that is unlocked when you upgrade to the paid version of the tool, so I guess it’s a moot point, but I just thought I would throw it in there.
Text Tools is a bit glitchy on Chrome. At least the version I’m playing with right now.
For the life of me, I can’t switch between the various tabs in the analysis mode on Chrome. I’m stuck in overview mode and can’t get into the juicy stuff like “Compare” where you analyze your URL vs the analysis of the competition.

That said, on Firefox everything is fine.
I envision a productive TF IDF workflow to work like this:
- Analysis of the competition
- Comparison against your content
- Optimization of your content
- Re-comparison against your content
- Publish
Text Tools allows you to copy and paste your page’s text into the tool itself. If you make changes to the content, you can simply edit the content in the tool, and re-analyze to see how you’ve done.
Website Auditor only compares against URLs. You either need to make changes to your live content or publish your content in a Google doc and have the tool analyze that.
It’s not a deal-breaker, but it takes time and its annoying.
Now Surfer takes at all to another level and gives you a “Content Editor” feature which gives you keyword stuffing completion rates on the fly.
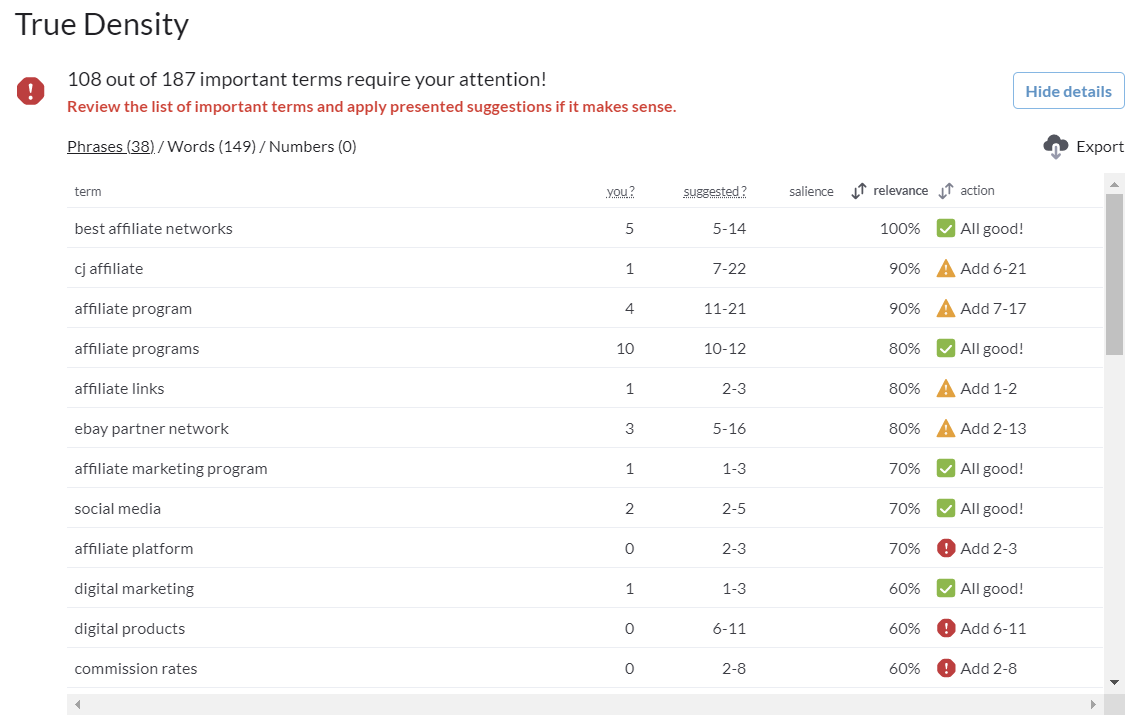
This makes Surfer super easy to work with.
Accuracy (Winner: Surfer)
As my team and I were playing around with Text Tools, we started noticing something strange.
Let’s say you analyze a keyword like “keyword cannibalization”.
When comparing the result vs my article on keyword cannibalization, you’ll find a result that looks like this:

You’ll notice that for the word “strategy” my content (yellow line) gets a zero because I don’t have that word on my page.
But what you’ll find is that even though it appears that the average is about 3.4, I would just need to add the word “strategy” once to jump up to adequate numbers.
I talked to the developer Michael Kaiser about this (a lovely guy by the way), and he said his tool denotes the y-axis as a “weight”, calculated internally. And a lot of the time, adding a word once to an article is enough to satisfy the weight requirement.
This is fine, but I’m more looking for actual guidance on how many times each word should appear in the article.
Website Auditor delivers that but it has a critical flaw…

Website Auditor doesn’t take word count into consideration!
If I have a 500-word article and everyone else has a 1000-word article on page 1, it will still give me guidance as if I had 1000 words, causing me to over-optimize. Sheesh.
So again, Surfer steals the show.
Surfer’s TFIDF algorithm is called True Density, which is a little bit different, but in my opinion, more accurate.
It also breaks down the guidance between words, phrases, and numbers.

And of course, it pulls the win in the accuracy category because of this algorithm and the important fact that it takes word count into consideration.
Cost (Winner: Website Auditor)
Unfair competition. You can’t compete with free.
Our Choice: Surfer SEO
![]()
Text Tools has a lot of things going for it. I’d much rather work on the cloud and perform my edits inside a tool so I can do a quick reanalysis.
Website Auditor is free, but it has its flaws in terms of accuracy.
At the end of the day, I’m looking for a cloud-based solution that gives me guidance, on a granular level, of the niche average density of keywords for each phrase and word. For this, I’m sticking with Surfer.
FAQ
What Is TF IDF SEO?
TF IDF SEO is the process of optimizing your content’s keyword density with the guidance of the algorithm known as TF IDF.
How Does TF IDF Work?
TF IDF works by calculating the frequency of a term that appears in a document (TF) with an offset that decreases the value of commonly used words, such as “and” (IDF) to get a more accurate representation of how important the term really is.
Does Google Use TF IDF?
It’s not likely Google uses TF IDF in its entirety. If Google does use it, it’s an advanced version that has evolved past its original understanding in the 1970s.
Who Invented TF IDF?
British computer scientist Karen Spärck Jones invented TF*IDF.
Can TF IDF be negative?
No. Both values TF and IDF can never be negative.
Conclusion
I hope this article has helped clear things up regarding the extremely useful, yet often misunderstood, TF*IDF analysis.
You’ve not only learned the mathematics behind it but also how it applies to on page SEO and creating relevance in your articles.
You’ve also seen some test results of how optimization shows up in the top 10 of Google SERPs, as well as a comparison of the most popular tools on the market.
If you have any questions, please use the comment box below.

